


Notebooks, Data App Builders, and IDEs in the Age of AI
Preswald: An IDE as easy to use as a notebook?

In the world of tools, simplicity wins… until it doesn’t. Tools succeed by solving a specific problem well, but that success often seeds their own obsolescence. The tool becomes a Swiss Army knife, wielded for jobs it was never designed for. Spreadsheets, for example, weren’t meant to replace databases, but they’ve been forced into that role for years. The same is now happening with notebooks.
Notebooks, like Jupyter/Hex, are the darling of data teams for exploratory analysis. They’re fast, intuitive, and enable storytelling in code. But as workflows scale from linear analysis to end-to-end systems, the cracks begin to show. And when cracks show, the market for better tools opens wide.
That’s the opportunity now. AI is an inflection point. It enables tools to move from specialized, one-off utilities to systems that handle entire workflows without the friction of transitioning between tools. If you’re building a tool for data teams today, don’t stop at solving a niche problem. Build for the workflow, not the feature.
📒 Why Notebooks Succeeded
The first thing to understand about notebooks is why they work. Successful tools don’t solve every problem; they solve one problem better than anyone else. For notebooks, that problem was exploratory data analysis.
Low Barrier to Entry. Open a browser, type a few lines of Python, and you’re running analyses. No setup, no overhead.
Immediate Feedback. Write code, run it, and see results instantly. It’s a dopamine loop for problem-solving.
Data tools like pandas and visualization libraries like matplotlib plug in easily. The ecosystem is the tool.
Storytelling in Context. Code, graphs, and narrative live side by side, making it easy to share insights.
These traits made notebooks the perfect tool for exploratory analysis. But they also hardcoded its limitations.

🌀Why Notebooks Are Cracking Under Pressure
Think about what a modern data pipeline looks like:
Ingestion: Pull data from multiple, messy sources.
Transformation: Clean, normalize, and engineer features.
Modeling: Train and validate machine learning models.
Deployment: Serve predictions in real-time or scheduled pipelines.
Monitoring: Track drift, performance, and data integrity over time.
Every step introduces complexity that notebooks weren’t designed to handle. Here’s why:
Sequential Nature. Notebooks execute code in order, with dependencies between cells. If you need modularity or reusability, you’re out of luck.
Lack of modularity. Code reuse and building components across workflows is challenging.
Collaboration Bottlenecks. Version control in notebooks is an exercise in frustration. Simultaneous editing feels like a game of chicken.
Deployment. Notebooks don’t help you ingest data or deploy a model. they stop at analysis. Teams fill the gaps with a messy patchwork of tools.
Production Pain. Moving notebook code into production isn’t simple—it’s a rewrite. That duplication is a waste of time and a breeding ground for bugs.
This isn’t a critique of notebooks. It’s a natural consequence of a tool being stretched beyond its design. The smarter move is to ask: What does the next tool look like?

🛡️Why Traditional IDEs Fall Short + The Next Generation
IDEs like VSCode are powerful, but they bring baggage. Configurations, environment management, and debugging pipelines can feel heavy-handed for data teams used to the simplicity of notebooks. These tools assume software engineering as the primary use case, not data science or machine learning.
Key limitations of traditional IDEs for data teams:
Setup Overhead: You need to configure environments, install dependencies, and set up projects before you can even start experimenting.
Feedback Lag: IDEs aren’t optimized for the rapid, iterative feedback loops that data exploration requires.
Workflow Gaps: They don’t integrate out-of-the-box with orchestration tools, or deployment environments.
Context Switching: Jumping between IDEs, notebooks, and other tools disrupts focus and slows down development.
If we were to design a tool from scratch to address the challenges of modern data workflows, what would it look like? Let’s distill this into a set of principles.
Modularity from the Start. Reusable components should be easy to create. For example, if you’ve written a data-cleaning function, you should be able to use it across multiple projects without copying and pasting code.
Support for the Full Lifecycle. Tools should handle not just analysis but also ingestion, transformation, deployment, and monitoring. This eliminates the need to cobble together multiple tools.
Collaboration-First Design. Teams need tools that work well with version control and allow simultaneous editing. This is especially critical as data projects become more team-oriented.
Productionization: Moving from exploration to production should feel natural. The tool should make it easy to take what you’ve built in experimentation and deploy it without starting over.
AI Features. AI can automate repetitive tasks, suggest optimizations, and provide visibility into workflows. For example, AI could generate a pipeline from a notebook or recommend improvements to a model.
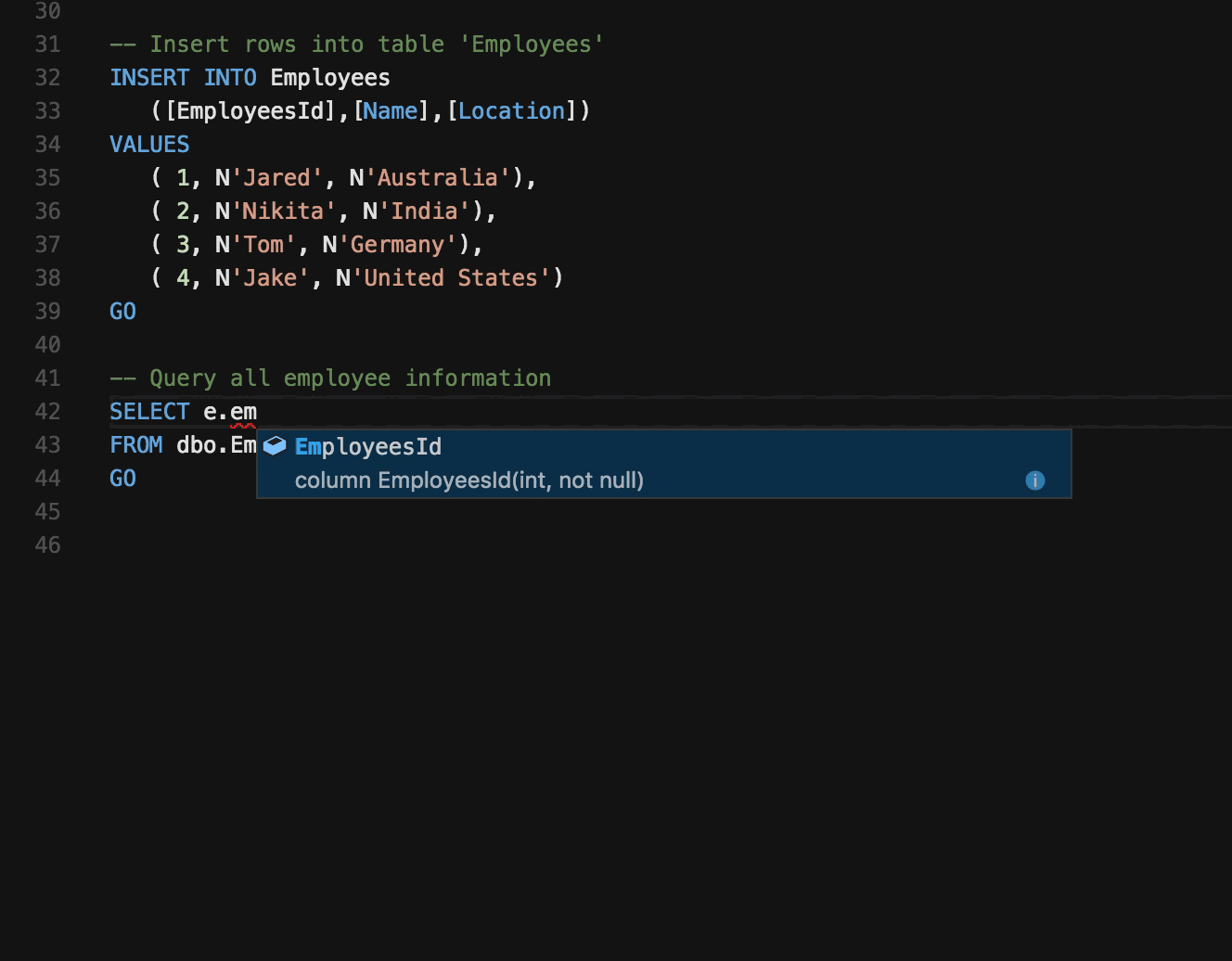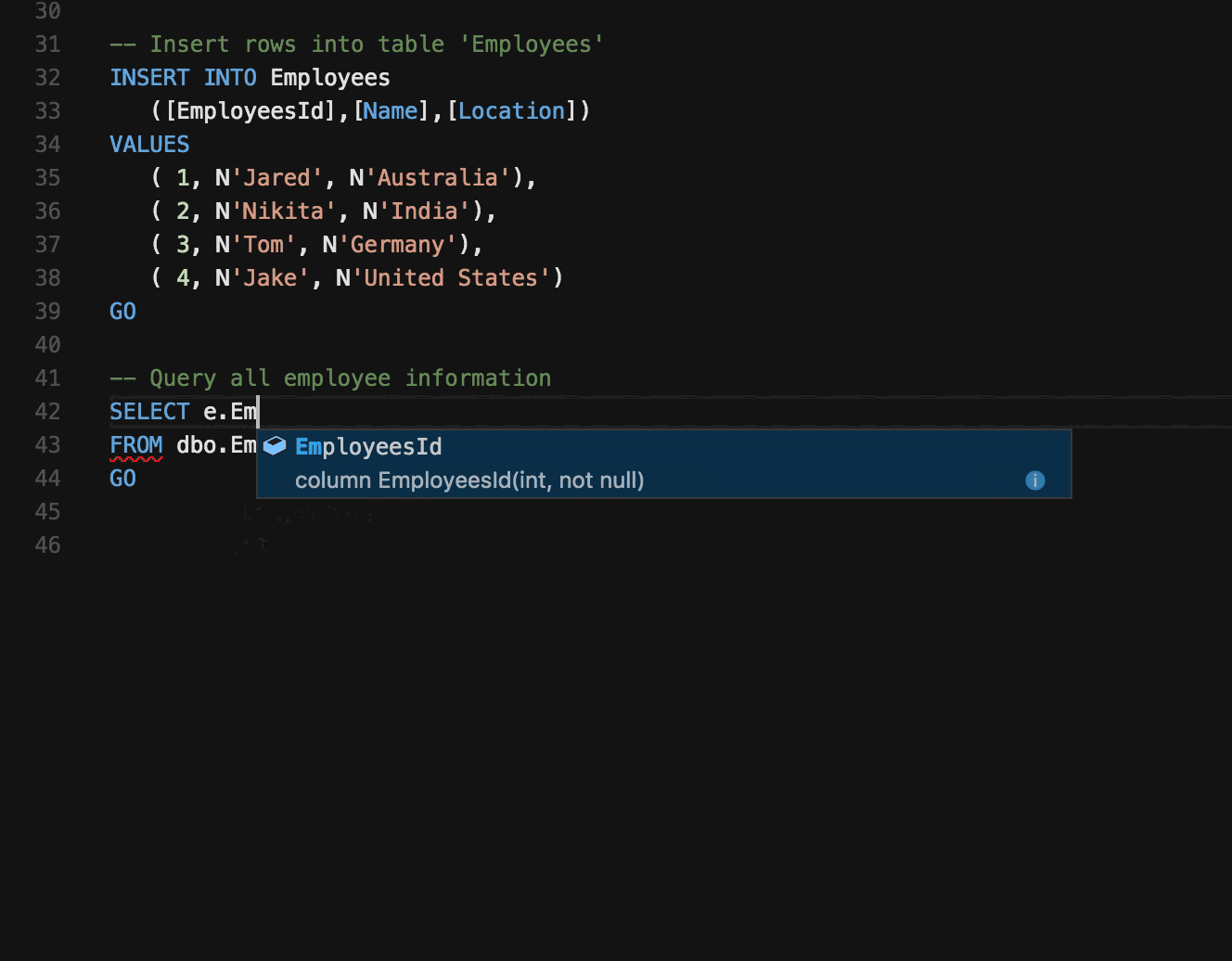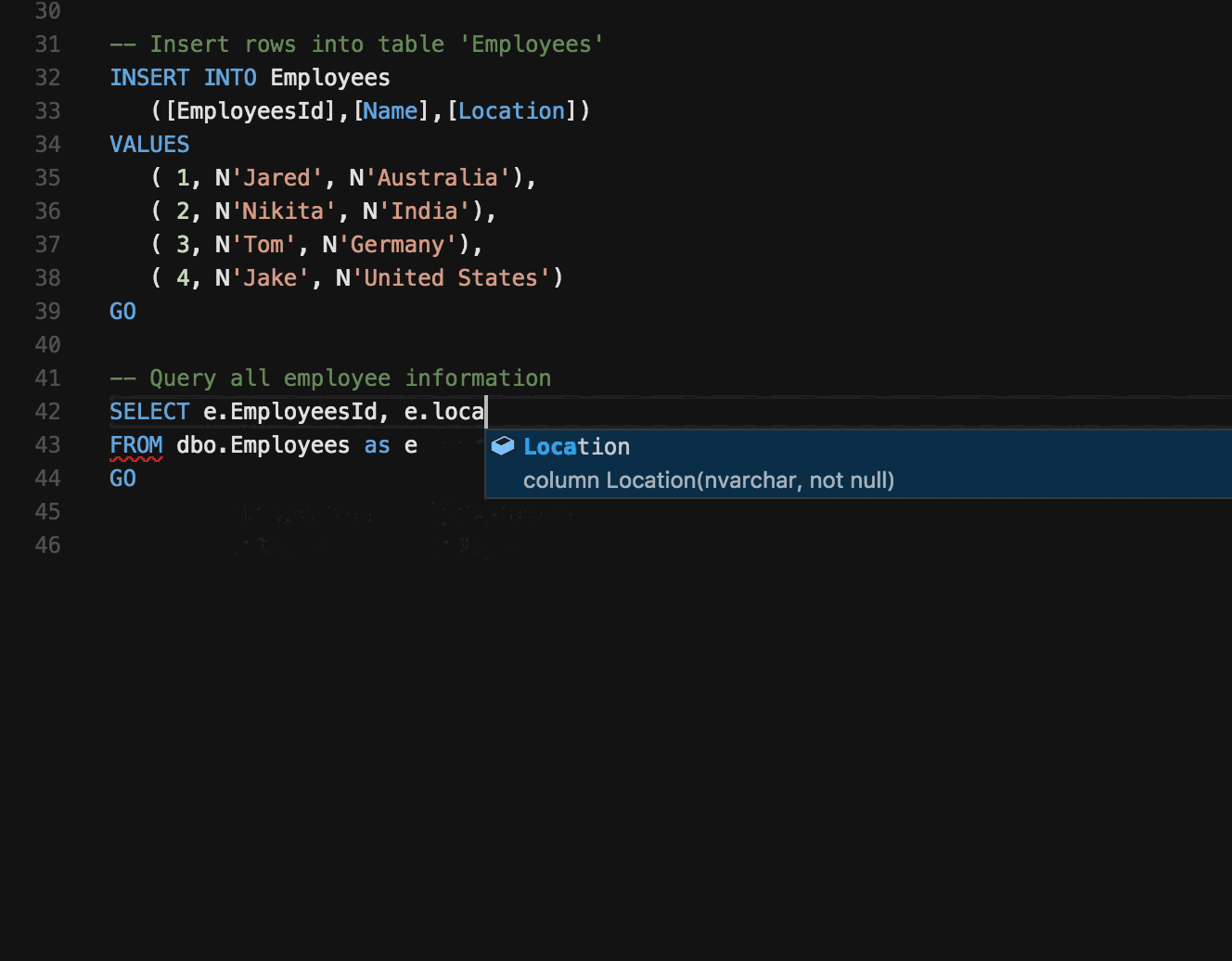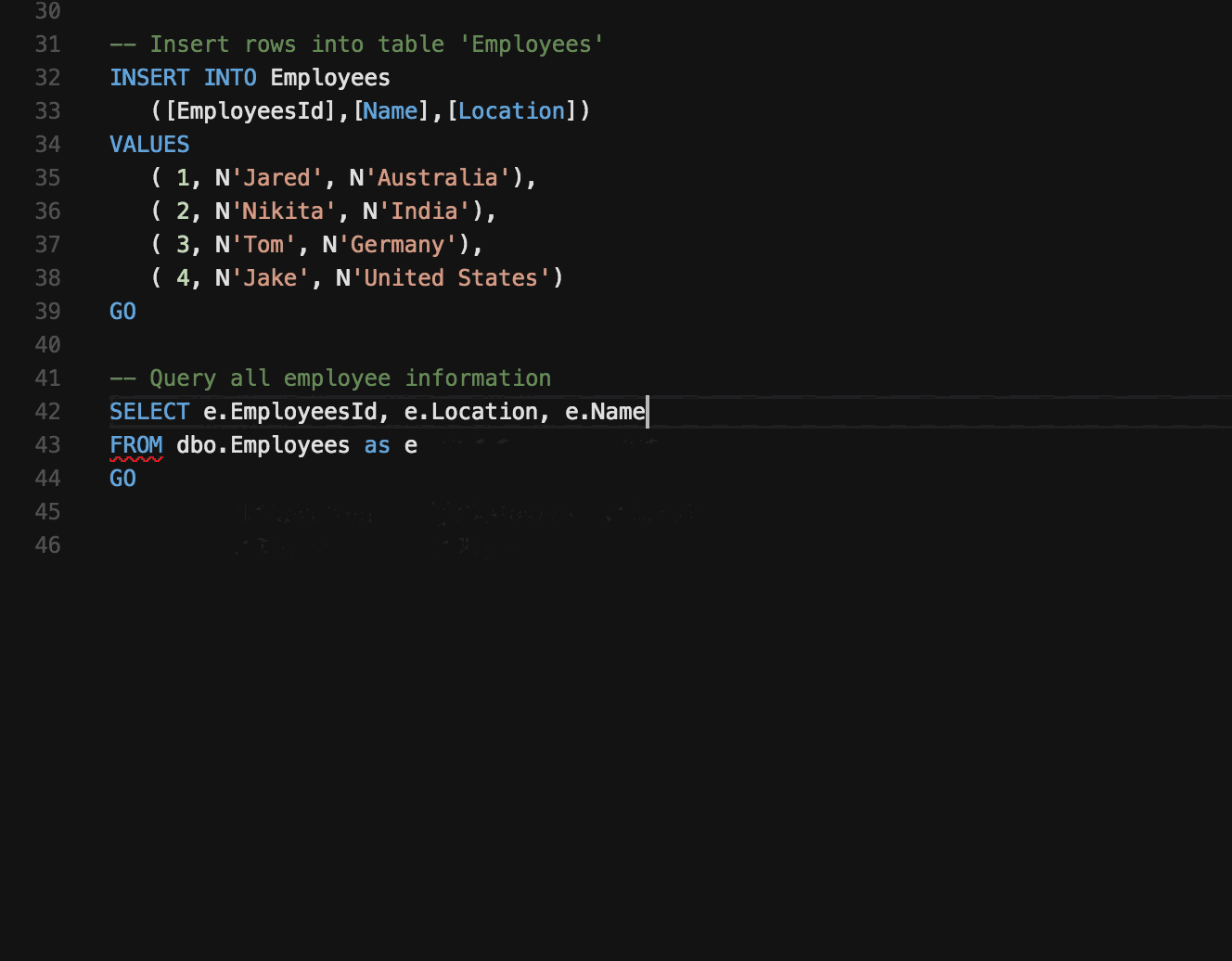
🤖 Preswald: Lightweight Meets Production-Ready
One of the secrets of building great tools is recognizing the pain people have gotten so used to, they think it's normal. Setting up an analytics stack is exactly that kind of pain. You cobble together tools like dbt, Airflow, and Snowflake, wade through endless configuration files, and debug obscure connection issues, all before you write a single line of analysis.
Preswald doesn’t replace the tools you already use; it makes them work together easily. And it does this not by introducing yet another standalone platform but by living inside VS Code, the environment you’re already using. Preswald’s job is to make the analytics stack setup so smooth, you forget it’s happening.
It combines the strengths of notebooks, IDEs, and data app builders into a single, lightweight solution.
Preswald acts like a co-pilot for your stack. You start with a simple command, and it walks you through setting up your stack step by step.
Example: When connecting to Snowflake, Preswald generates the required config file, validates your credentials, and even runs a test query to make sure everything works.
Get pre-built templates. Analytics stacks tend to follow predictable patterns. Preswald capitalizes on this by offering prebuilt templates for common setups.
Example: Want dbt for transformations, Airbyte for ingestion, and some basic dashboards? Preswald can scaffold the entire setup in seconds, with all the pieces pre-wired to work together.
Testing. Preswald catches errors before they happen. It validates your YAML, JSON, and SQL files as you write them, flagging missing fields or misconfigurations.
Example: If your dbt model references a table that doesn’t exist, Preswald warns you immediately.
Better Dependency Management. Forget manually setting up Python environments or Docker containers. Preswald automates this, ensuring your stack runs smoothly out of the box.
Example: It detects which dependencies you need and sets up a virtual environment with the correct versions.
Preswald doesn’t reinvent orchestration. Instead, it integrates with tools like Airflow or Dagster, helping you define pipelines without the usual configuration headaches.
Example: Write a simple pipeline definition, and Preswald translates it into a fully operational Airflow DAG.
Preswald closes the gap between experimentation and production.
💡The Opportunity
The best tools change how you think. Spreadsheets turned numbers into something interactive. Notebooks made code a storytelling medium.
The next generation of tools will do something bigger. They’ll let you move from idea to production in a single, easy flow. They’ll make complexity invisible. And they’ll use AI to handle the busywork so you can focus on the hard parts.
This is the kind of shift that creates billion-dollar companies. Not by being incrementally better, but by creating a new default.
If you’re building tools for data teams, this is the moment to bet big. Build for the future, not the past. The tools we use today won’t survive the workflows of tomorrow—and that’s where the opportunity lies.
Sign up for the Preswald Waitlist today to get early access.