


Applying computational graph principles to notebooks 📓
Bringing order to the chaos of notebooks with DAG thinking


Notebooks are immensely powerful for exploratory data analysis and prototyping, but they’re often a victim of their own flexibility. Hidden dependencies, unpredictable execution, and inconsistent outputs can turn even the best work into an unmanageable tangle. By applying principles from DAGs, we can impose structure on notebooks without sacrificing their interactivity, creating workflows that are both reliable and reproducible.
Common Problems in Notebook Workflows
Traditional notebooks lack the rigor needed for complex or collaborative workflows. Let’s break down the main issues:
🔸Cells as "Free Nodes". Users can execute cells in any order, even if one depends on another. This freedom often leads to broken workflows or unexpected results.
🔸Hidden Dependencies. Notebooks rely on a global namespace, but relationships between variables and cells are implicit. This makes it hard to trace what depends on what.
🔸Unpredictable Execution. Skipping, reordering, or re-running cells can introduce inconsistencies. Variables may persist or reset in unexpected ways.

How DAG Principles Address These Problems
DAGs are a natural fit for solving these challenges. A DAG is a directed graph where nodes (operations) are connected by edges (dependencies) and have no cycles. Applying DAG principles to notebooks can:
Enforce order: Cells execute in a clear, dependency-driven sequence.
Improve reproducibility: Defined relationships ensure consistent outputs from the same inputs.
Enhance transparency: Explicit dependencies make workflows easier to debug and maintain.
This mirrors the approach of tools like TensorFlow, which represents computations as DAGs. Operations execute in sequence based on dependencies, ensuring order, reproducibility, and clarity.
Comparing DAG-Oriented Tools and Notebooks
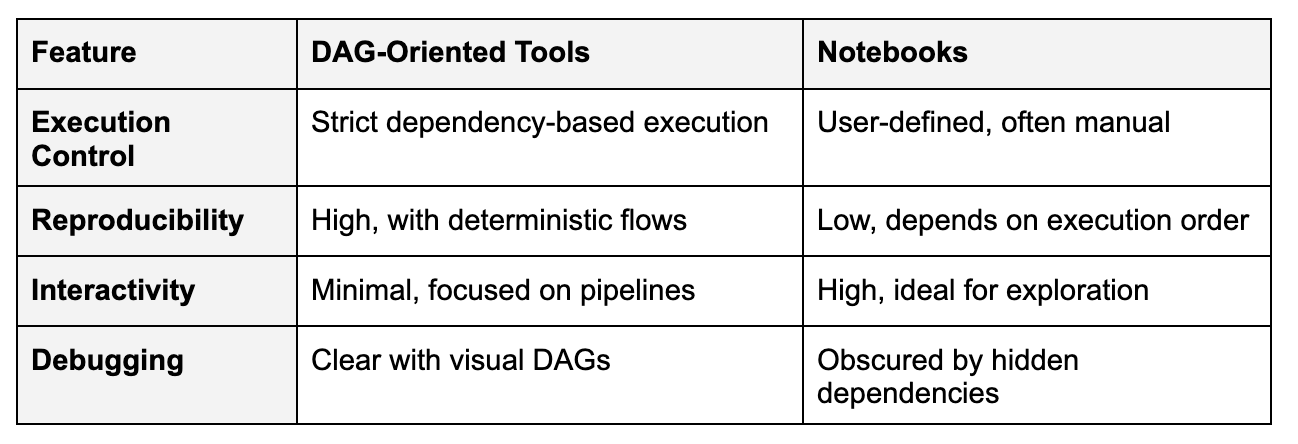
The challenge is merging the rigor of DAGs with the interactivity of notebooks, creating workflows that are both flexible and robust.
The TensorFlow Analogy
To understand the power of DAGs in notebooks, consider how TensorFlow builds computational graphs. TensorFlow operations are organized as a DAG: nodes represent operations, and edges define their dependencies. This approach provides:
1️⃣ Order: TensorFlow ensures that operations execute only when all their dependencies are resolved. For example, if you’re training a neural network, the model parameters can’t update until the gradients have been computed. No matter how the operations are defined in the code, the graph makes sure they run in the correct order.
2️⃣ Reproducibility: TensorFlow guarantees that if you feed the graph the same inputs, you’ll always get the same outputs. This goes beyond just getting consistent results. It helps with building workflows you can trust. When experiments need to be repeated or models need to be audited, this consistency is important.
3️⃣ Transparency: The graph is a clear, visual representation of your workflow. Every step and its dependencies are laid out, making it easy to understand what’s happening, spot inefficiencies, or debug errors. Tools like TensorBoard let you inspect the graph step by step, which is a huge advantage in complex workflows.
Now think of notebook cells: they’re like operations in a computational graph, but without enforced dependencies or execution order. This lack of structure is why notebooks often produce unpredictable results.
By applying DAG principles:
Cells become nodes in a graph: Think of each notebook cell as a node in a computational graph. For example, a cell that loads data could be the first node, and a cell that processes the data could depend on it. This structure ensures that cells can only run in the right order, like nodes in TensorFlow’s graph.
Dependencies are explicit.: In a DAG-structured notebook, you explicitly define which cells depend on others. For example, you’d say, “This preprocessing cell depends on the data-loading cell.” If the data-loading cell changes, all downstream cells update automatically. This eliminates hidden dependencies so the entire workflow stays consistent.
Execution becomes predictable. With DAG principles, cells execute only when their dependencies are satisfied. If you modify a preprocessing step, you don’t have to guess which cells need to be rerun—the notebook knows and handles it for you. This means your outputs are always aligned with your inputs, and you can trust the results.
Key Insight: Just as TensorFlow’s computational graphs bring discipline and clarity to complex machine learning workflows, implementing DAG principles in notebooks introduces the same rigor to exploratory workflows, without losing their interactivity.
The Takeaway
Notebooks and DAG tools operate in different worlds, but the principles of one can profoundly enhance the other. By borrowing concepts from DAGs- order, reproducibility, and transparency- we can elevate notebook workflows to be more reliable and scalable while retaining their exploratory nature. Bring structure to chaos and turn experiments into something that scales.
Love this. Exactly what we’re building at https://www.fabi.ai/
Lots of interesting challenges when it comes to state management and mutable objects.